
# I. Avoiding bias in AI: how a representative workforce empowers due diligence-grade data for financial decision-making
Bias can exist in artificial intelligence (AI) and machine learning. As the world’s largest ESG technology company committed to providing the most comprehensive dataset on ESG risks, a part of RepRisk’s work involves proactively mitigating biases in our dataset by leveraging the value of a representative research staff.
As stated in part one of our series on AI and machine learning in ESG, RepRisk’s unique combination of cutting-edge technology and human intelligence is the best approach to delivering speed and driving the scale of our dataset without sacrificing data quality or granularity.
There is a human behind every piece of technology. Algorithms will reflect the bias of whomever programmed it, or in the case of supervised machine learning, the person who labels the dataset used to train the algorithm. With that in mind, it is important to shed more light on how the human element is critical to ensuring high-quality machine learning-based solutions.
# II. How does bias in AI occur?
Algorithms leverage vast amounts of data to generate outputs for users – be it a decision on a loan application, which ad to show in a newsfeed, or which restaurant to recommend.
Bias in AI – and in its outputs – is pervasive. It originates from human bias being programmed into an algorithm via the data labels used to train the algorithm. There are many recent examples of these biases being revealed. Amazon discovered a significant bias against women in their recruiting algorithm. The algorithm was trained on resumes of those previously hired to Amazon, whose workforce was predominantly white males. Because of this, the algorithm relegated CVs containing the word “women,” eliminating candidates who attended a women’s college. 1
This is one example of an algorithm that picked up on human biases in its training dataset. However, many human biases are implicit, so their existence in a person or algorithm goes unchecked due to a lack of conscious awareness – and humans are sometimes left conducting damage control once the bias comes to light in their deployed technology. The key to eradicating biases is acknowledging their likely existence and proactively instilling measures for detection and prevention.
# III. How do humans interact with AI at RepRisk?
Human interaction with algorithms is at the heart of RepRisk’s work. Since 2007, RepRisk has produced the largest, highest-quality annotated (human-labeled) dataset on ESG risks – a dataset which took the equivalent of 1,000 years of working hours to create.
The dataset spans a close-to 20-year daily time series on ESG risks related to hundreds of thousands of companies and is annotated by human analysts across 80 languages. It is used to train RepRisk's algorithm to precisely identify and assess ESG risks.
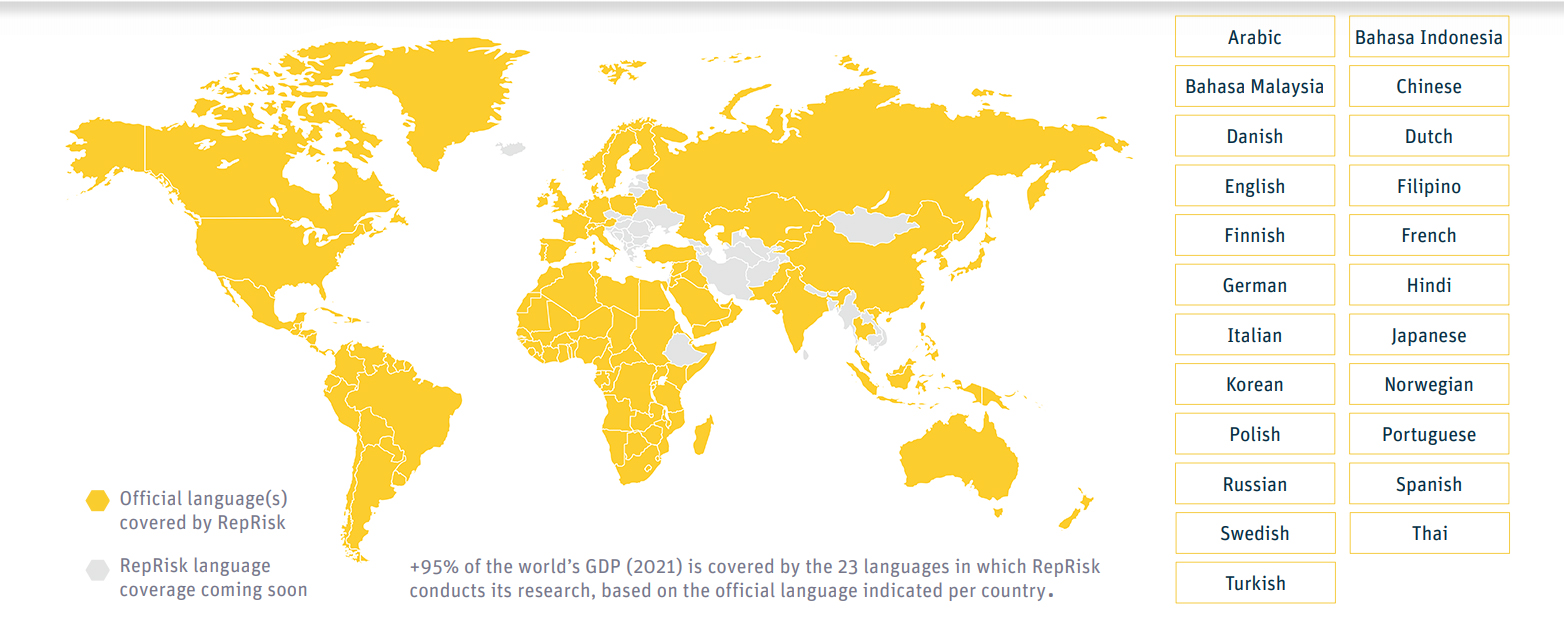
Today, more than 150 highly skilled and carefully trained analysts use a transparent, rules-based methodology to train, optimize, and refine the algorithm by curating the results of a daily AI screening.
The human review of the algorithm’s results helps eradicate flawed output that the algorithmic logic may have produced. For example, during the Black Lives Matter demonstrations in early 2020, an article published by one leading newspaper analyzed the role of corporates with respect to racial inequality. The text included negative and positive assessments of companies. However, because of the negative sentiment the article included, the artificial intelligence alone associated all companies mentioned with negative ESG factors – something RepRisk analysts overrode and corrected.
# IV. It starts with humans
Having a rules-based methodology and continued refinement of the algorithm does not de facto prevent biases – they need to be prevented and mitigated by the people who train the algorithm and those who label the dataset and make the rules by which it is labeled.
A lack of representation in AI and research teams can perpetuate bias and leave stones unturned, which is why representation is an intentional cornerstone of RepRisk’s research team. Combined, the team speaks more than 40 languages and is 40% male and 60% female – the diversity shapes a dataset that significantly reduces the potential for bias in AI.
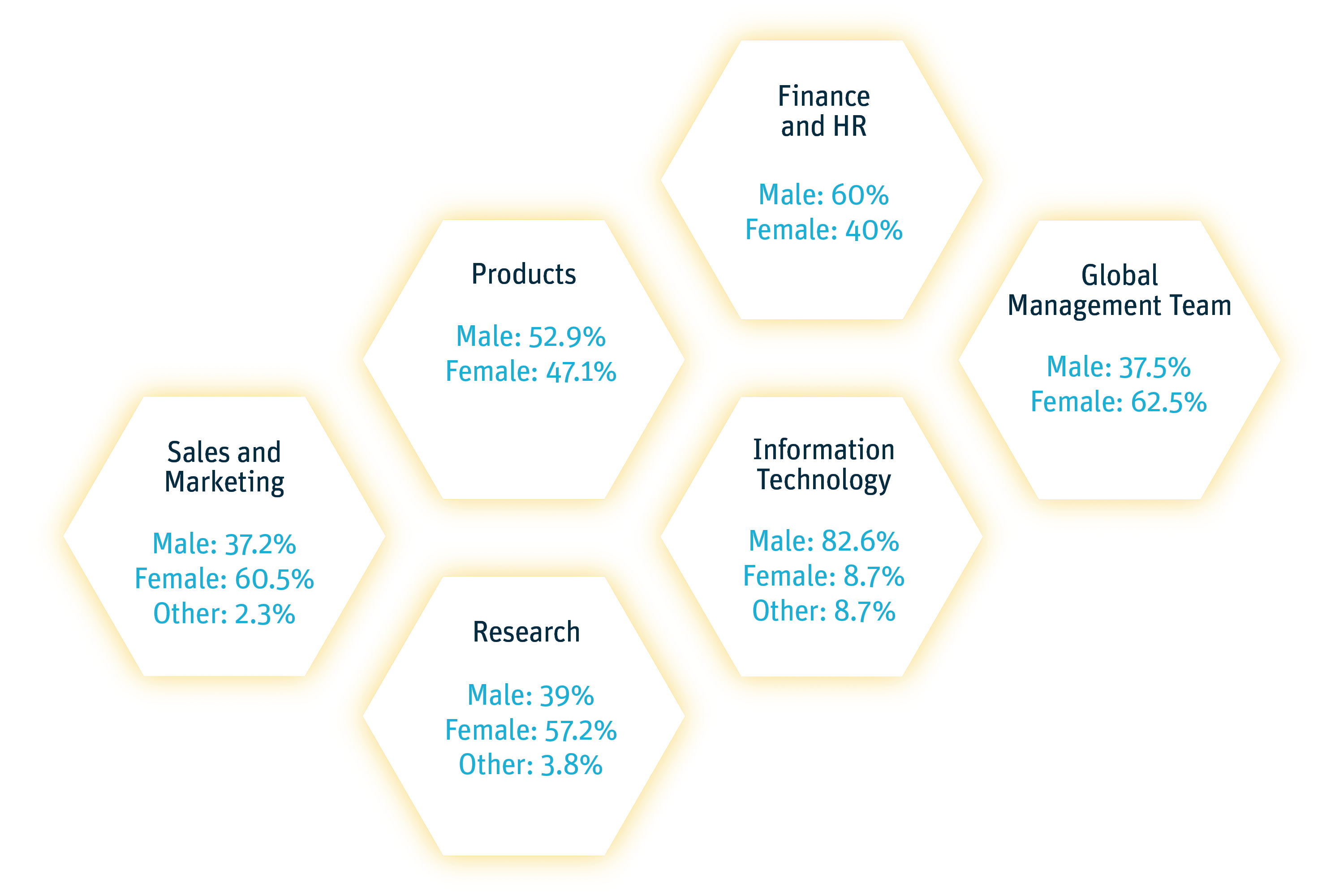
The representative staff and minds help preclude biased results – especially when it comes to sensitive or difficult assessments that do not clearly fall within any of the pre-determined guidelines. These are tackled via group discussion, incorporating the team’s combined experiences on the cultural, technical, and linguistic context of an ESG risk incident – thereby arriving at more nuanced decisions than the AI alone. This is particularly important in conversations like:
Determining the severity to assign certain risk incidents, especially those around sensitive social issues like gender inequality or migrant labor. This is a topic that we will evaluate more closely in part three of our series on AI and machine learning.
How to carefully expand our research scope to include topics like racism/racial inequality.
# V. Combining the best of both worlds
RepRisk is committed to driving positive change via the power of data, and AI and ML can enhance human capabilities and amplify those efforts. The first step is ensuring the quality and integrity of our data, and diversity in our human workforce is a key element. Combining the best of both worlds, AI and human intelligence, allows us to provide clients with a comprehensive, daily updated, due diligence-grade dataset on ESG and business conduct risks that serves as a reliable foundation for financial decision-making.


